
最終更新日:
NeurIPS2019参加報告(前編)

1.はじめに
スキルアップAIの小縣です。NeurIPS2019に参加してきましたので、その様子を本ブログにてお伝え致します。私は普段、ディープラーニング講座を担当していますので、本ブログではE資格試験対策という視点も入れながらレポートしていくことにします。E資格試験は、日本ディープラーニング協会が実施する資格試験で、AI実装力を証明できる試験として注目されています。
Conference on Neural Information ProcessingSystems(NeurIPS)は、AI分野における世界最大規模の国際会議です。元々NIPSと略されていたのですが、この単語が性的表現にも用いられるということが問題になり、2018年からはNeurIPSと略されることになりました。 NeurIPSでは、ニューラルネットワークを中心とした機械学習関連分野の研究成果が発表されます。参加チケットは簡単には入手できず、ポスターセッションですら採択されることが難しいという、非常に人気の高い国際会議です。
2.会場(Location)
NeurIPS2019の会場は、バンクーバー中心地に位置するバンクーバーカンファレンスセンター(VCC)です。VCCは、NeurIPS規模の国際会議を余裕をもって行えるくらい大規模な建物でした。また、内海に面しており、室内からの眺めは絶景でした。メイン会場であるWest Exhibition B+Cは、非常に広く、椅子をざっと数えたところ6000席くらいありました。大型スクリーンは6枚あり、ライブ会場のようでした。
-

VCC外観(WEST)
-

VCC外観(EST)
-

VCCメイン会場(West Exhibition Hall B+C)
-

VCCミーティングスペース
-

VCC 吹き抜け
3.参加者数(Number of registrations)
NeurIPSの参加者数は年々増え続けており、今年はなんと過去最高の約12,000名(EXPOを含めると約13,000名)でした。昨年は参加チケットが申し込み開始から12分で売り切れてしまったため、今年は公平を期すために抽選制となりました。主催者側の発表によると、抽選への申し込みは15,000名で、そのうち半分が当選したということなので、当選確率は50%ということになります。
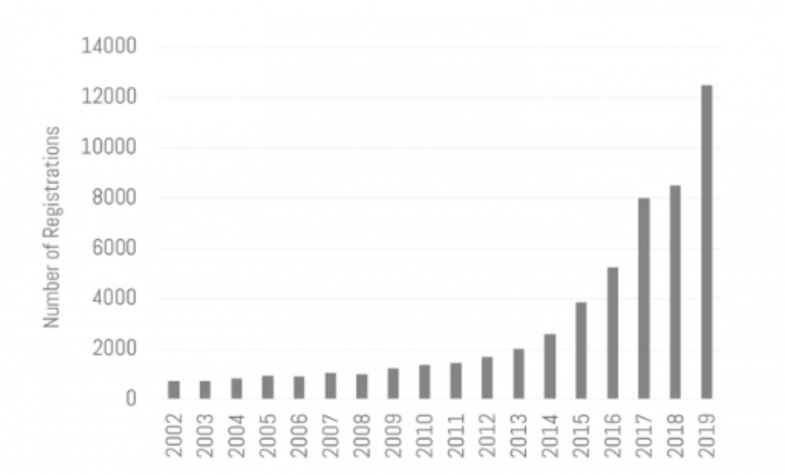
参加者数の推移(Opening Remarksより引用)
これだけ参加者がいると、会場内の移動も大変です。通路はいつもこんな感じでした。
-
 会議室から会議室への移動
会議室から会議室への移動
4.投稿数と採択数(Papers)
論文投稿数も年々増加しており、今年は6743件となり、昨年に比べ39%も増加したそうです。このうち採択されたのは1428件で、採択率は21%となります。1428件の内訳は、口頭発表(orals)が36件、口頭発表(spotlights)が164件、ポスター発表のみ(posters only)が1228件です。
-
-
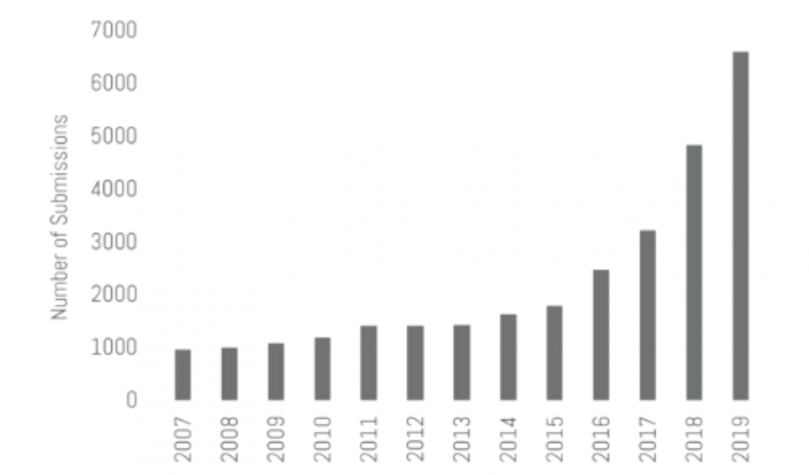
論文投稿数の推移(Opening Remarksより引用)
-
-
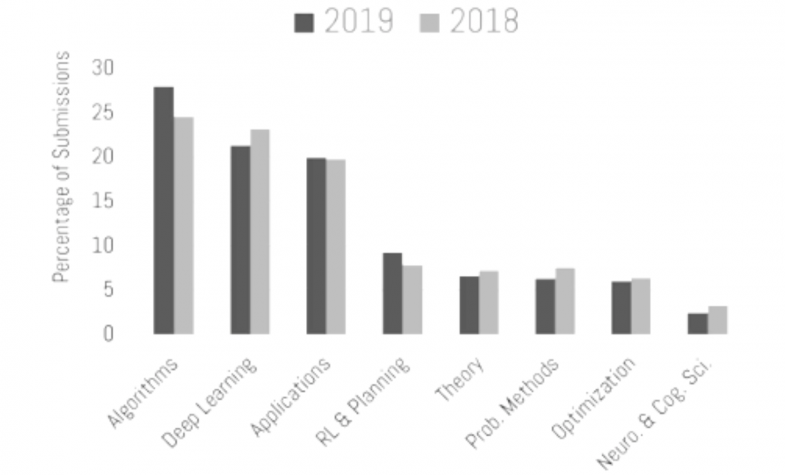
投稿された論文の内訳(Opening Remarksより引用)
5.表彰(Awards)
採択された論文のうち、特に優秀な論文に対して賞が贈られます。NeurIPSで受賞した論文は、その研究自体も重要ですが、その後の研究で引用されることが多いので内容を押さえておくと、研究の流れを掴みやすくなると思います。ただし、表彰されるのは理論研究分野が多いので、E資格試験に直接的に出題される可能性はそれほど高くないと思います。表彰論文は、以下のブログで確認できます。
NeurIPS 2019 Paper Awards : https://medium.com/@NeurIPSConf/neurips-2019-paper-awards-807e41d0c1e
6.会場での登録(Registration)
会場に到着したら、まず登録を行ってバッジをもらわなければなりません。12,000名もいると、会場での登録も一苦労です。主催者側からは、オープンニングの前日にあたる日曜日中に登録することを勧めるという案内が届いていたので、日曜日に登録しに行ったところ、全く並ばずに登録を済ませることができました。しかし、月曜日の朝は、朝6時30分開始にもかかわらず、数時間待ちの長蛇の列ができたそうです。登録を済ませると、パンフレット2冊と記念品としてのマグカップがもらえます。
-
 パンフレット2冊とマグカップ
パンフレット2冊とマグカップ
7.日程概要(Schedule)
NeurIPS2019の日程概要です。
12月8日(日) :NeurIPS EXPO (AIやDLの産業応用に関するワークショップやトーク)
12月9日(月) :オープニング、チュートリアル
12月10日(火)〜12月12日(木) :招待講演、一般講演、ポスターセッションなど
12月9日(月)〜12月11日(水) :スポンサーブース
12月13日(金)〜12月14日(土): ワークショップ
12月14日(土) :クロージング
* チュートリアル(tutorials)
チュートリアルでは、ある特定のテーマに対するアプローチの仕方やモデル構築の例などを紹介します。例えば、「Imitation Learning and its Application to Natural Language Generation」というチュートリアルでは、翻訳などの言語生成タスクを模倣学習系の強化学習手法を用いて解くという方法が紹介されました。チュートリアルは全部で9件でした。
* スポンサーブース(Sponsors)
スポンサーブースでは、スポンサー企業が自社サービスを紹介します。日本の企業も何社か入っていました。どのスポンサー企業も人材獲得に力を入れているようで、世界中でAI人材が不足しているということがよくわかります。スポンサー一覧はこちらです。
-
 スポンサーブースの様子
スポンサーブースの様子
* ポスターセッション(Poster session)
ポスターセッションでは、研究内容を著者自身がポスターで発表します。1会場にポスターを並べるため、参加者が一堂に会します。通路は始終大混雑で、興味のあるポスターに近づくこともままならない状況でした。各ポスターにおける人の集まり具合にはばらつきがあり、私の感覚では、ポスターの絵や図がわかりやすい、プレゼンターの話がうまい、研究テーマがおもしろいものは、足を止める人が多い印象でした。研究者もプレゼン力が重要ですね。
1ポスターセッションあたりのポスター枚数は多い時で200枚くらいあるのですが、時間が2時間と短く、しかも人の多さで自由に移動できないため、当然全て見て回ることはできません。結局、著者ときちんと話をできたのは、1ポスターセッションあたり5枚~10枚くらいでした。ポスターセッションは合計6回ありました。
-
 ポスターセッションの様子
ポスターセッションの様子 -
 ポスターセッションの様子
ポスターセッションの様子
* ワークショップ(Workshop)
ワークショップでは、特定のテーマに興味のある人が集まり、研究発表やディスカッションを行います。複数のワークショップが並行して開催されるため、人はかなりばらけました。強化学習など人気のテーマは会場が埋まっていましたが、ヘルスケアにおける公平な機械学習(Fair ML in Healthcare)のような分野を限定したワークショップは、人の入りも少ない傾向が見られました。ワークショップは、全部で51件でした。
-
 ワークショップの様子
ワークショップの様子
8.多様性と社会参加(Diversity & Inclusion)
NeurIPSは近年、人種の多様性や障害者の社会参加にも力を入れており、今回のNeurIPS2019でも、Women in Machine Learning、Black in AI,、LatinX in AI、Queer in AI、Jews in AI、{Dis}Ability in AIという6つの団体のワークショップが本プログラムと並行で開催されていました。各団体は、それぞれの対象者がAI業界において活躍の幅を広げることをミッションに掲げています。ワークショップでは、各団体に該当する人たちが集まり、AI業界において存在感を高めるための方法を議論したり、研究成果などを共有していました。
9.託児サービス(ChildCare)
NeurIPS2019は子育て世代にも配慮しています。会場内には、託児場所が用意されており、参加者は完全に無料で利用することができます。ただし、事前予約が必要です。事前予約は11月9日までだったのですが、11月10日以降は申し込みフォームが閉じられており、追加募集もなかったため、事前予約だけで定員に達していたのだと思われます。一定の需要があったということですね。
折角の機会なので、私も利用してみました。朝から夕方まで預けることができて、食事も用意してくれますし、遊び道具も揃っています。保育士の数は子供3人に1人くらいの割合でした。託児所の場所は会場内なので、いつでも子供の様子を確認することができ、安心して預けることができました。運営事業者は、このような託児サービスを専門的に提供しているKiddieCorp社でした。ここまでのサービスを無料で提供しているのは、日本では考えられないですね。
10.イベント管理アプリ(Mobile app)
NeurIPS2019では、Whovaというイベント管理アプリが公式的に利用されました。Whovaでは、全てのスケジュールを閲覧&ブックマークできますし、チャットの機能もあり他の参加者とコンタクトをとることができます。Whovaを利用している参加者は、アプリ上の表示で10,000人となっていましたので、ほぼ全参加者が利用していることになります。開催期間中の合計で約300のmeetupが立ち上がっており、参加者同士の交流促進に大きな効果を発揮していたと思われます。
11.ライブ配信(Streaming service)
実は、NeurIPS2019の様子は、Slides Liveというサービスによって、ライブ配信されていました。その動画は記録されており、会期が終わった今でも、誰でも無料で視聴することができます。
この動画が非常に有難かったです。複数のプログラムが異なる会場で同時に進行している場合、物理的に全て参加することができません。この動画があると、あとで確認することができますので、1つのプログラムに集中することができます。また、会場だと、席によってはスライドが見えづらかったり、外部騒音やエコーで聞きづらかったりしたのですが、動画ですと、音質と画質が非常によく、むしろ動画の方が快適に視聴できました。さらに、動画ですと、興味のあるところを何度も再生しながら理解を深めることができます。弊社の講座でも動画教材を提供しているのですが、NeurIPSの動画配信を通じて動画の力を改めて認識しました。
12.注目キーワード(Keywords)
NeurIPSでは、理論から応用まで、幅広い分野の研究成果が発表されますので、人によって注目する点は大きく異なると思います。ここでは、私が個人的に気になったキーワードを紹介したいと思います。各キーワードには件数も併記しています。この件数は、公式ウェブサイトにおけるScheduleページでの検索結果です。件数の多い順に着目しているわけではありませんので、件数は参考程度に捉えてください。これらキーワードに興味があるのでもっと勉強してみたいという方は、ぜひ弊社ディープラーニング講座へお越しください。
● graph(ポスターセッションで173件)
○ 折れ線グラフのグラフではなく、グラフ構造のグラフです。173件のうちほとんどグラフニューラルネットワークに関する研究です。
○ グラフ構造に向いているデータは、化合物や人間関係など、世の中に沢山あります。それらデータをニューラルネットワークでモデル化するための研究がここ数年かなり盛り上がってます。
○ 2020年版のE資格シラバスにはまだ入ってませんが、いずれシラバスに入ってくるでしょう。
● generalization(ポスターセッションで137件)
○ 汎用的に使えるモデルを作ろうという研究がこのキーワードでヒットします。
○ ディープラーニングは、ある程度精度の高いモデルを作れるようになってきたので、もっと汎用的に使えるようにしていこうという流れが出てくるわけですね。
● GAN(ポスターセッションで115件)
○ GANは2014年に提案されました。その後、様々なGAN派生系が提案されており、その数は300~500くらいあると言われています。
○ NeurIPS2019でもGANの枠組みを利用した新しい手法がいくつも提案されていました。
○ E資格でもGANは頻出です。GANの派生系がよく出題されるので、代表的なGAN派生系を押させておくと良いでしょう。
● object detection(ポスターセッションで22件)
○ 物体検知は、アノテーション(正解データを作ること)作業が大変です。
○ この点を克服するための提案がいくつか見られました。
● semantic segmentation(ポスターセッションで18件)
○ セマンティックセグメンテーションもアノテーション(正解データを作ること)作業が大変なタスクです。
○ この課題を克服するための提案がいくつか見られました。
● bayes (ポスターセッションで110件、bayesian optimizationはそのうち20件)
○ bayesian optimization(ベイズ最適化)は、ニューラルネットワークのハイパーパラメータ探索などに使われる手法です。
○ bayesian optimization(ベイズ最適化)以外のbayesは何をテーマにしているのかというと、その多くがベイズニューラルネットワークをテーマにしています。
○ 従来のニューラルネットワークはパラメータを確定的に扱いますが、ベイズニューラルネットワークでは確率的に扱います。これにより、柔軟にモデリングできる、不確実性をうまく扱えるようになる、過学習を防げる、などの良さがあると言われています。
○ ベイズニューラルネットワークは、論文の件数が示しているように、これからもっと盛り上がりそうな予感がしています。
○ ベイズニューラルネットワークは、E資格にはまだ出題されたことがありませんが、技術動向は追いかけておいた方が良いと思います。
● Adversarial example(ポスターセッションで38件)
○ 敵対的サンプル(Adversarial example)とは、データに摂動(ノイズのような小さな揺らぎ)を与えただけで、機械学習モデルが分類エラーを起こしてしまうサンプルのことで、この性質を悪用することを敵対的攻撃(Adversarial arttack)と言います。高度なニューラルネットワークモデルを簡単に騙せてしまうことから、セキュリティ面で問題になっています。敵対的サンプル(Adversarial example)を初めて指摘した論文はこちらです。
○ この敵対的サンプル(Adversarial example)に関する論文が38件ありました。
○ 敵対的攻撃(Adversarial arttack)を完璧に防ぐ方法がまだ見つかっていないため、今後もこの分野の研究は続いていくでしょう。
● Lottery ticket(ポスターセッションで3件)
○ 2019年に宝くじ仮説(THE LOTTERY TICKET HYPOTHESIS)という論文が発表されて、大きな注目集めました。
■ The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural NetworksJonathan Frankle, Michael Carbin(ICRL 2019, Best Paper). https://openreview.net/pdf?id=rJl-b3RcF7
○ 宝くじ仮説とは、「ニューラルネットワークにおいて、学習が上手くいくネットワーク構造とパラメータ初期値の組み合わせは、当たりくじのように働いているのでないか。パラメータの多いモデルを学習させると精度の良いモデルになりやすいのは、当たりパラメータをひく確率が高まるからではないか。」という仮説です。
○ 今回のNerurIPSにおいては、宝くじ(Lottery ticket)の解明を試みている論文がありました。
少ないデータで如何にうまく学習させるか、というテーマも多くあり、こちらも一つのトレンドですね。
・One-shot (ポスターセッションで8件)
・Zero-shot (ポスターセッションで8件)
・Few-shot (ポスターセッションで24件)
・Semi-supervised (ポスターセッションで29件)
・Self-supervised (ポスターセッションで15件)
・Weakly supervised (ポスターセッションで3件)
Supervised learningは、ラベル付きデータを使って学習させる方法を指します。
Unsupervised learningは、ラベルなしデータを使って学習させる方法を指します。
Semi-supervised learningは、ラベルなしデータとラベル付きデータの両方を使って学習させる方法を指します。
Self supervisedは、データ自身の中に教師を設定して学習させる方法を指します。ラベルを与えていないため、ある種の教師なし学習なのですが、従来の教師なし学習で行う特徴抽出やクラスタリングといった手法と区別したいときにこの言葉が使われます。
Weakly supervised learning(weak supervisionともいう)は、弱い教師がついたデータで教師あり学習を行う方法を指します。Weakly supervisedに関しては、弊社顧問の杉山将教授も注目されています。
- https://emtiyaz.github.io/aip_iith_workshop_2019/slides/Sugiyama.pdf
- https://www.slideshare.net/MLSE/ss-97568525
13.NeurIPS全体の印象
ポスターセッションの会場を歩いていると、GAFAMと共同研究している大学が多いということが一目でわかります。そのなかでもGoogleのロゴは、他4社よりも多いように思いました。
発表者や参加者の顔ぶれを見ると、北米系と中国系が多いように思いました。残念ながら日本人の参加者はかなり少なく、おそらく数十人くらいと思われます。
研究者のうち女性が2~3割くらい占めていたのには驚きました。日本でディープラーニングを扱っている女性は本当少ないので、世界と日本の違いを感じました。

配信を希望される方はこちら
また、SNSでも様々なコンテンツをお届けしています。興味を持った方は是非チェックしてください♪
公開日:














