
最終更新日:
データ分析の様々な作業を自動化!DataRobot + TableauによるAIモデル自動作成と予測結果の可視化

こんにちは、スキルアップAIの藤本です。
近年、蓄積されたデータを分析をする業務が増加する一方、分析を行う人材は不足しています。それにより、AIの自動化のため機械学習自動化プラットフォームを導入する企業が増加しています。しかし、単に予測結果を得るだけでは、予測の傾向などを掴みきれず、ビジネスの意思決定に活かしづらいことがよくあります。そのため、予測結果を可視化し、どのような傾向があるのか確認することで、意思決定をより迅速に行うことができるようになります。また、可視化を通して新しいビジネスインサイトを獲得することにも役立つでしょう。
そこで、この記事では機械学習自動化プラットフォームである、DataRobotによって機械学習モデルを作成し、Tableauによって予測結果を可視化する方法をご紹介します。
1.Tableau とは?
Tableauは、データ分析に関して専門外の人であっても、容易にデータ加工・レポート作成・分析を行うことができるソフトウェアパッケージです。その中で、Tableau Desktopはデータを接続し、可視化・分析するためのソフトウェアです。Tableau Prep BuilderはTableauでの分析用にデータを組み合わせたり、加工、クリーニングすることができます。今回使うExcelのデータセット以外にもMySQLなどの様々なデータベースと接続することができます。
2.DataRobot とは?
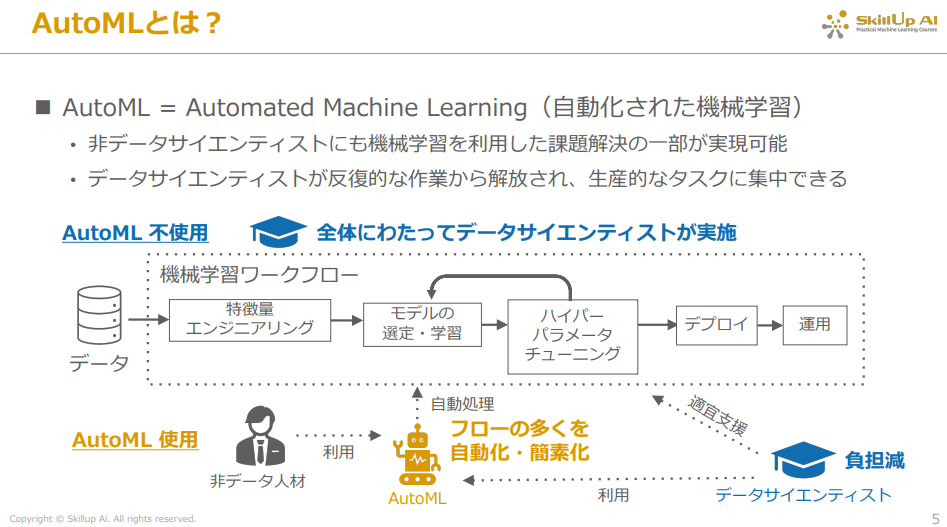
まず、AutoMLは今まで手作業で行っていた特徴量に対する前処理の部分や、モデルの選定などの時間のかかる作業を機械で自動化することで、数多くのモデルを試すことができ、他の生産的な作業に集中して取り組める等の利点があります。このような機械学習を自動化する製品に、DataRobot社が開発した機械学習自動化プラットフォームである「DataRobot」があります。こちらはAI導入による外注費や、モデルの偏りなどのリスクを一手に解決してくれる等の利点を持っています。また、データサイエンティストをこれらの機械学習自動化プラットフォームで代替する企業も増加しています。
3.準備
この章では、次章以降で扱うDataRobotとTableauの環境構築を行っていきます。
まず、Tableau DesktopとTableau Prep Builderはこちらのリンクからそれぞれインストールができます。
次に、DataRobotはこちらのリンクからトライアル環境を作成できるため、順次メールアドレスの登録を行ってください。
また、Tableauのワークブック内でPythonを使うため、そのためのAPIであるtabpyとそれに付随するライブラリとバージョンをインストールします。
まず、tabpy 等のインストールですが、mac ならターミナル、windows なら Anaconda Promt で以下を実行していきます(以降は、ターミナルやAnaconda Promtをまとめてコンソールと表記します)。
pip install tabpy==2.4.0
tabpy 以外の必要なライブラリのインストールについては以下をコンソールで実行していきます。
pip install requests==2.26.0 pip install pandas==1.3.4
最後にデータセットをダウンロードしていきます。今回使うデータセットは、DataRobot社が提供している「通信業者のサービスのレコメンデーション」についてのデータセットを使います。こちらのリンクから「Telco_Next_Best_Offer.zip」をダウンロードして解凍してください。
以上で環境構築は終わりとなります。それでは、DataRobotを使ったモデル作成を行っていきましょう。
4.DataRobot によるモデルの作成〜デプロイ
ここではDataRobotを使って、用意したデータセットの分析を行っていきます。
まず、前章で作ったアカウント情報を基に、以下のサイトにログインします。
https://app2.datarobot.com/
ログイン直後に他の画面が表示されている場合は下記の画像のように左上の「DataRobot」ボタンからホーム画面に戻すことができます。
下記の画像のようにホーム画面に戻った後、右上の人のアイコンから「設定」を開きます。
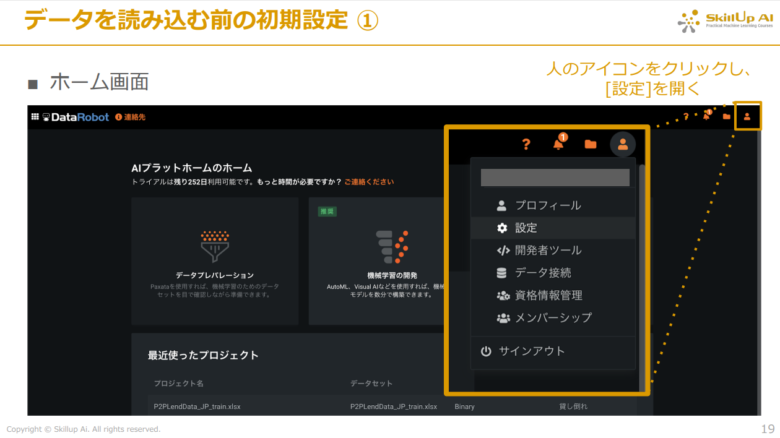
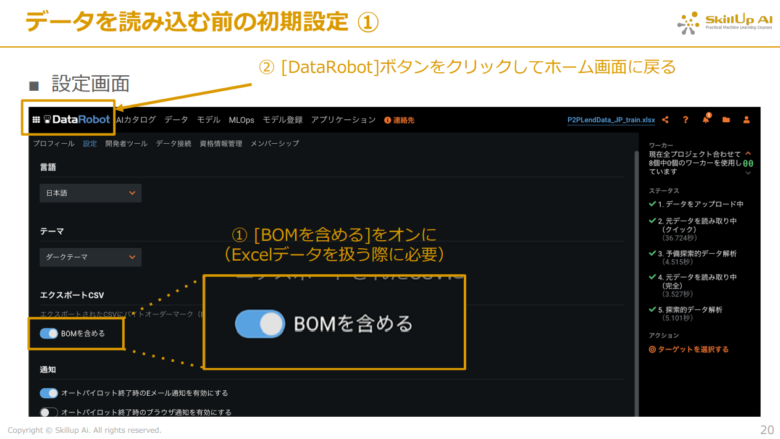
今回扱うデータはExcelファイルであるため、画面左の欄にある「BOMを含める」をオンにします。(BOM(Byte Order Mark)はファイルの先頭に3バイトを加えてエンコードを示すために使用されるバイトシーケンスです。)
オンにしたら再び左上の「DataRobot」ボタンからホーム画面に戻ります。
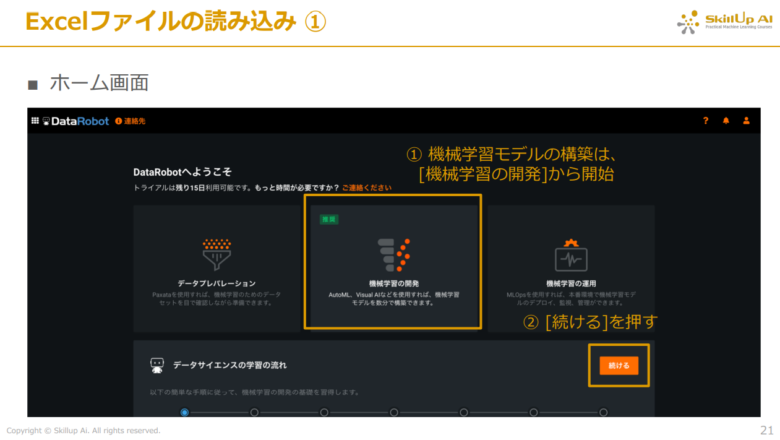
次に、用意したデータセットをDataRobot上で読み込ませる作業を行って行きます。
ホーム画面中央の「機械学習の開発」をクリックします。
遷移した画面中央にある青枠内にダウンロードした「Telco_Next_Best_Offer_train.xlsx」をドラッグ&ドロップして、xlsxファイルをアップロードします。
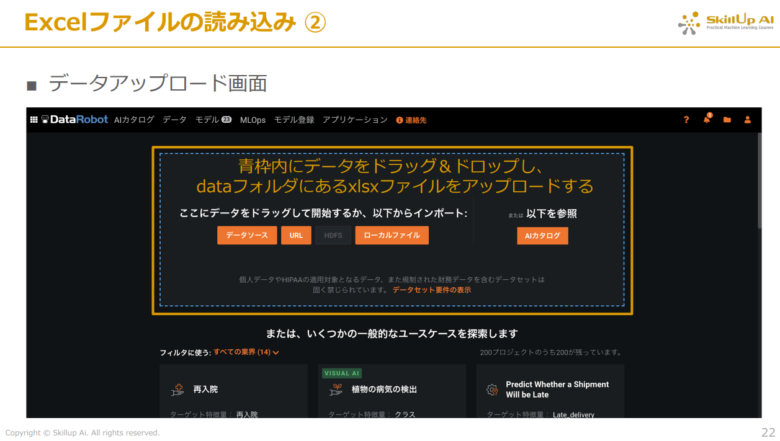
データのアップロードが終わると下記の画像のように、ターゲット選択画面に遷移します。
下記の画像のように、画面右下に「ターゲットを選択する」が表示されれば、アップロードが無事完了となります。
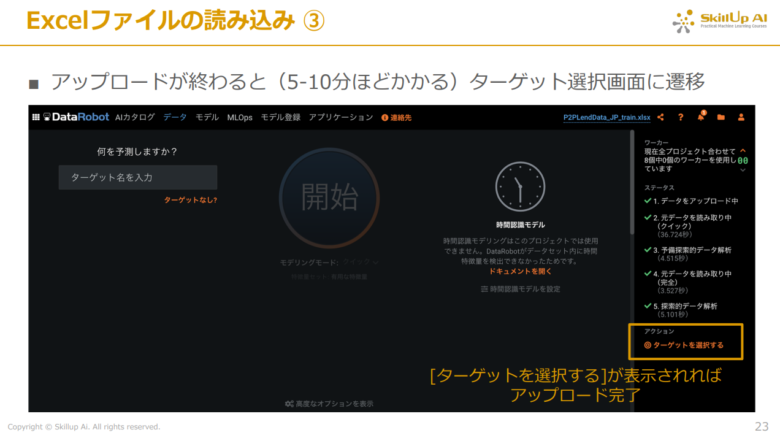
次に、今回予測したい対象(ターゲット)を選択します。
下記の画像のように画面左に表示されている、「ターゲット名を入力」に今回の予測対象である「提案プラン」を入力します。

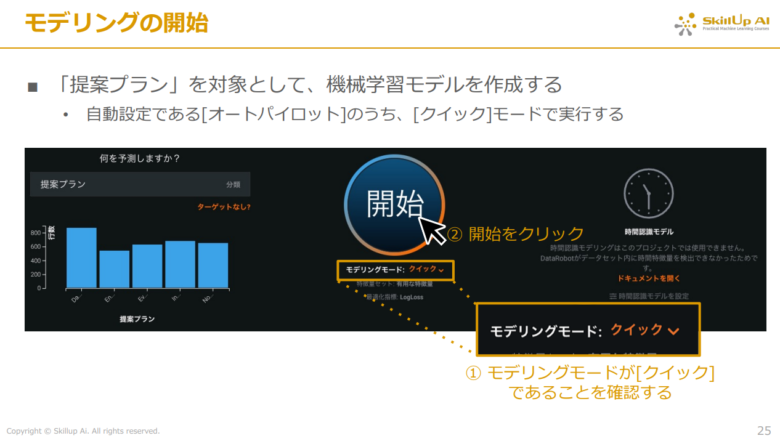
以上まででモデル作成の準備ができたため、早速モデリングを実行します。
下記の画像のように中央の「開始」ボタンをクリックするとモデリングが開始されます。(時間を短縮するために、「開始」ボタン下のモデリングモードをクイックにすると、通常の4分の1程度の時間で完了するため、素早く分析を行いたい場合におすすめです。)
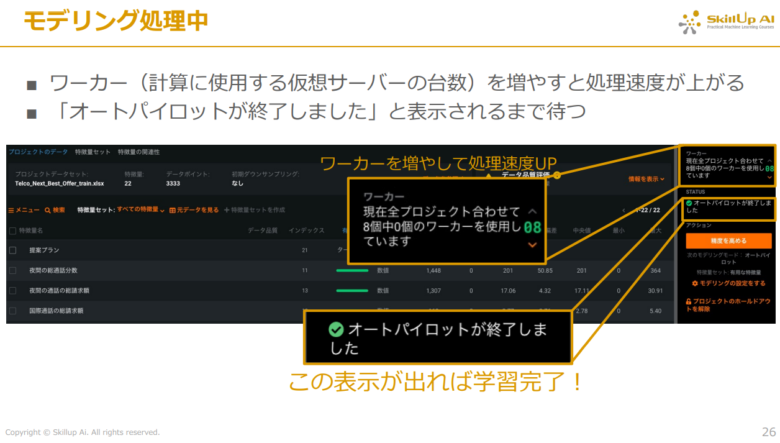
モデリングの処理が終了した場合、下記の画像のように右の欄に「オートパイロットが終了しました」という表示がされます。
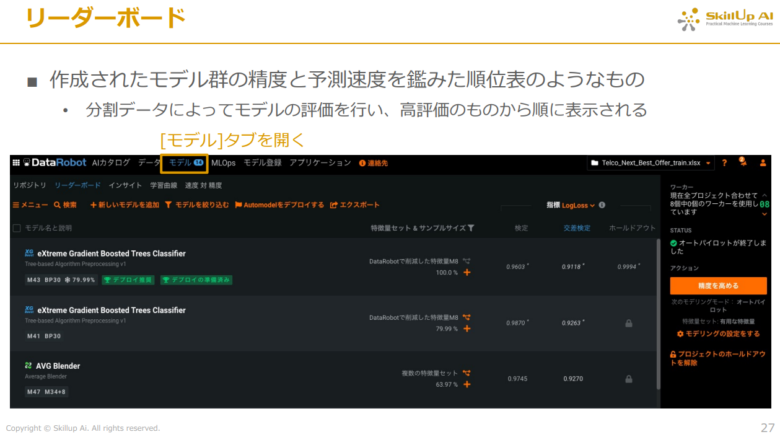
下記の画像のように上部の「モデル」タブを開くと、作成されたモデル群の精度や予測速度などを鑑みた順位表(リーダーボード)が表示されます。
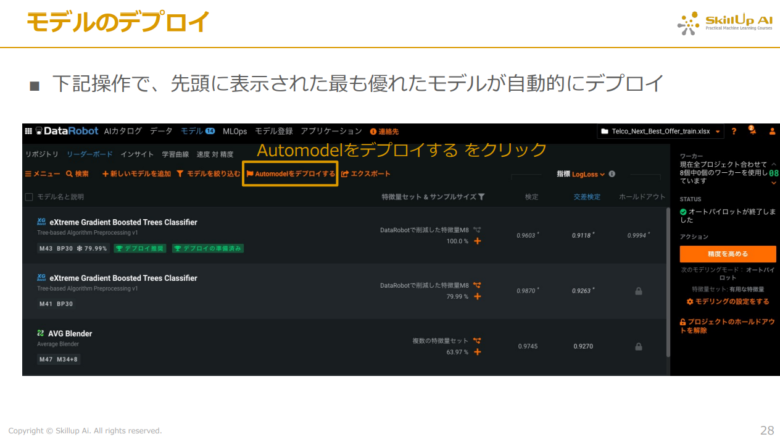
作成されたモデル群の中で最も優れたモデルをデプロイするため、画面上部にある「Automodelをデプロイ」をクリックすると、自動的に先ほどのリーダーボード最上位にあるモデルがデプロイされます。
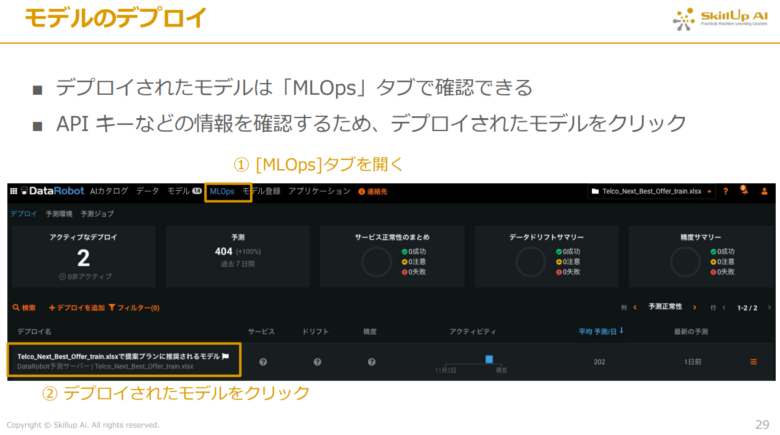
デプロイされたモデルについては画面上部の「MLOps」タブをクリックすると確認できます。そして、後でTableauで今回作成したモデルを使うことから、APIキー情報を確認するため、画面左下のデプロイされたモデルをクリックします。
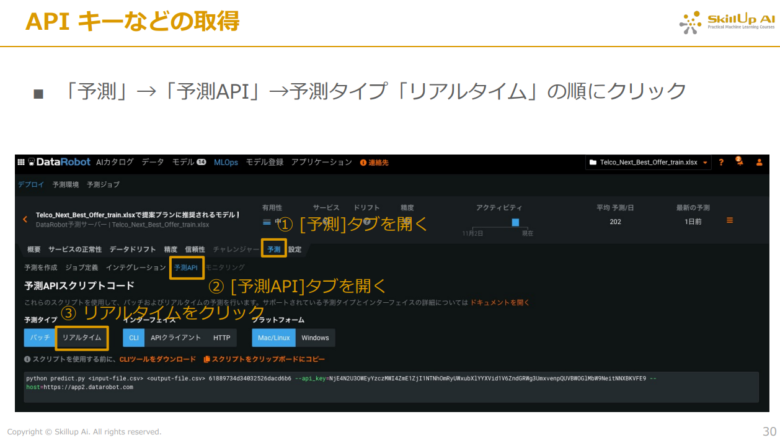
画面が下記の画像のように遷移したら、以下の手順で行っていきます。
- 「予測」ボタンをクリック
- 「予測API」ボタンをクリック
- 予測タイプの欄にある「リアルタイム」をクリック
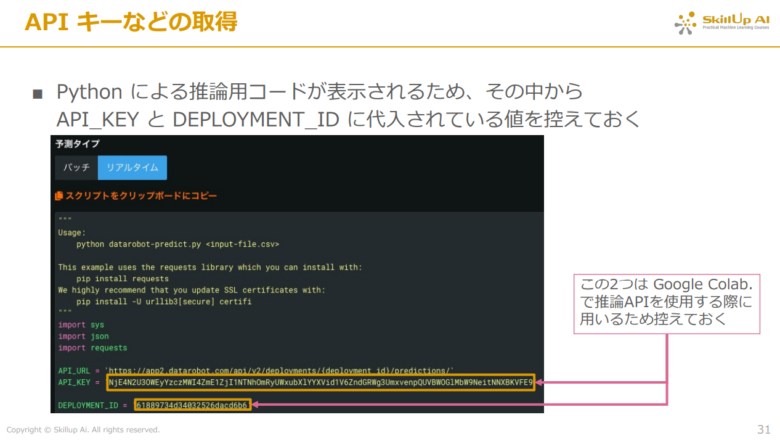
以上の手順から、Pythonによる推論用コードが表示されるため、その中から「DEPLOYMENT_ID」と「API_KEY」に代入されている値を控えておきます。
先ほど控えた「DEPLOYMENT_ID」と「API_KEY」を以下のPythonスクリプト内の14行目「DEPLOYMENT_ID」と17行目「API_KEY」の部分に代入していきます。このPythonスクリプトは「dr_prediction.py」として保存しておきましょう。
import json import requests import pandas as pd # DataRobot の REST API を使って予測を実行し、Pandas のデータフレームとして返す関数 def prediction( input_df # データソースからはデータフレームとして渡される ): # テストデータをCSVとして保存 input_df.to_csv('test_data.csv', index=False) # デプロイしたモデルに固有のID(要変更) DEPLOYMENT_ID = '控えたDEPLOYMENT_IDをここに代入' # API 利用のためのユーザ固有の認証キー(要変更) API_KEY = '控えたAPI_KEYをここに代入' # 推論のための URL API_URL = f'https://app2.datarobot.com/api/v2/deployments/{DEPLOYMENT_ID}/predictions/' # テストデータのCSVファイルをバイナリ形式で読み込み data = open('test_data.csv', 'rb').read() # HTTP リクエストのヘッダー部分 headers = { 'Content-Type': 'text/plain; charset=UTF-8', # 送信するデータのもとはテキスト形式 'Authorization': 'Bearer {}'.format(API_KEY), # 認証のためのキーの情報 } # REST API で推論を実行 predictions_response = requests.post( API_URL, # POST 先の URL data=data, # 送信するバイナリデータ headers=headers, # ヘッダー情報 ) # JSON 形式で返ってきたレスポンスをPythonの辞書形式に変換 prediction_json = predictions_response.json() # 辞書形式のデータを Pandas のデータフレームへ変換 ## predictionValues:各クラスの確率 ## deploymentApprovalStatus:予測が問題なく行われているかどうか(問題なければ APPROVED) ## Prediction:予測確率最大のクラス名 ## rowId:行数 df_prediction = pd.DataFrame.from_dict(prediction_json['data']) # 入れ子になっている辞書形式をテーブル形式に変換 df_proba = pd.json_normalize(prediction_json['data'], # 元データ record_path='predictionValues', # どの部分を展開するか meta='rowId') # 展開結果に付与したい内容 # 列にクラス名、行にrowID、値に予測確率を入れた表に変換 df_proba_pivot = df_proba.pivot(index='rowId', # どの列をインデックスに設定するか columns='label', # どの列を列に設定するか values='value') # それぞれの値にどの列を設定するか # 列全体に label という名称がついているが、不要のため削除 df_proba_pivot.columns.name = None # 各列名をわかりやすくするため、先頭に一律に「予測確率_」を追加 df_proba_pivot_added_prefix = df_proba_pivot.add_prefix('予測確率_') # 予測確率最大のクラス名の列を、予測確率のデータフレームに追加 df_proba_pivot_added_prefix['提案プラン'] = df_prediction['prediction'] # 入力データフレームの顧客ID列を、予測結果のデータフレームに追加 df_proba_pivot_added_prefix['顧客ID'] = input_df['顧客ID'] return df_proba_pivot_added_prefix # prediction 関数で返されるデータフレームのスキーマを定義する関数 # 参考:https://help.tableau.com/current/prep/ja-jp/prep_scripts_TabPy.htm def get_output_schema(): return pd.DataFrame({ '予測確率_Daytime plan' : prep_decimal(), # 小数型 '予測確率_Enhanced Voicemail Plan' : prep_decimal(), # 小数型 '予測確率_Evening call plan' : prep_decimal(), # 小数型 '予測確率_International call plan' : prep_decimal(), # 小数型 '予測確率_No Action' : prep_decimal(), # 小数型 '提案プラン': prep_string(), # 文字列型 '顧客ID': prep_int() # 整数型 })
以上でDataRobotでのモデル作成が終わりとなります。
次章では、ここまでで作成したモデルを使って、テストデータの予測とその可視化をTableauで行っていきます。
5.Tableau による予測結果の可視化
ここでは、Tableauでテストデータの予測とそのデータの結合、および可視化を行っていきます。
まず、コンソール上で以下を実行します。
tabpy
コンソールをそのままの状態にして、Tableauの方に移っていきます。
まず、Tableau Prep Builderを開くと、下記の画面が表示されます。
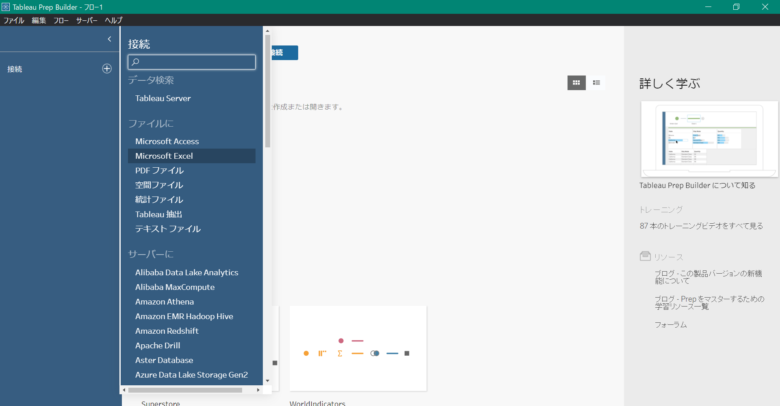
画面左の「接続」の横にある「⊕」ボタンをクリックして、今回使うテストデータの形式であるMicrosoft Excelを選択して、先ほどダウンロードした「Telco_Next_Best_Offer_test.xlsx」を選択します。
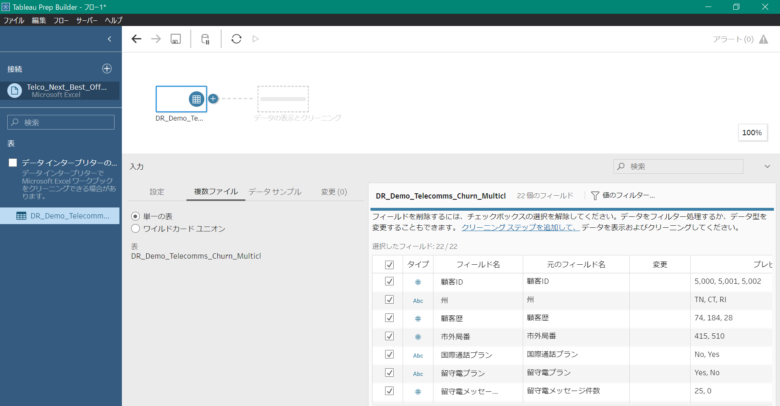
下記の画像のようになったら、画面中央の「DR_Demo_Telecomms_Churn_Multicl」のアイコン横の「⊕」ボタンをクリックして、「スクリプト」を選択します。
下記の画像のように画面が遷移したら、以下の手順で行っていきます。
- 接続タイプを「Tableau Python(TabPy)Server」に選択
- ファイル名の欄にある「参照」ボタンをクリックして保存したPythonスクリプト「dr_prediction.py」を選択
- 関数名の欄に実行したい関数名である「prediction」を入力
以上の手順を順に行うと、自動で推論が行われます。
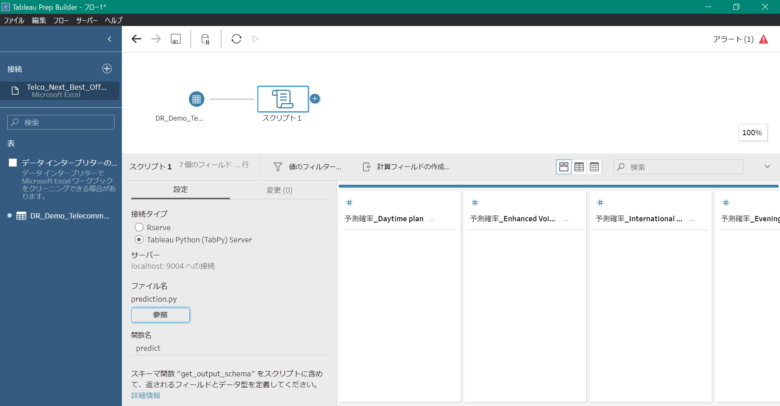
推論が行われた結果、下記の画像のように表示されます。
右下にそれぞれの項目における確率の分布が可視化されています。
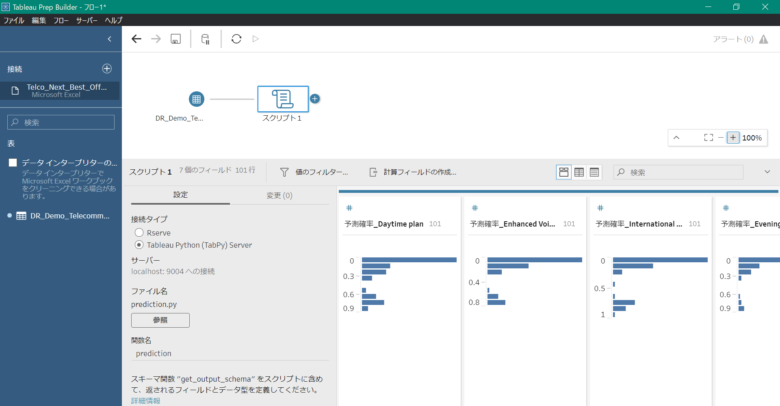
次に、予測結果を元のテストファイルである「Telco_Next_Best_Offer_test.xlsx」と結合するため、画面中央の「DR_Demo_Telecomms_Churn_Multicl」のアイコンをドラッグした状態で「スクリプト1」のアイコンまで移動させると、横に「結合」という表示がされるため、そこまでドラッグ&ドロップします。
そうすると、自動でデータの結合が行われ、下記の画像のように結合されたデータが表示されます。
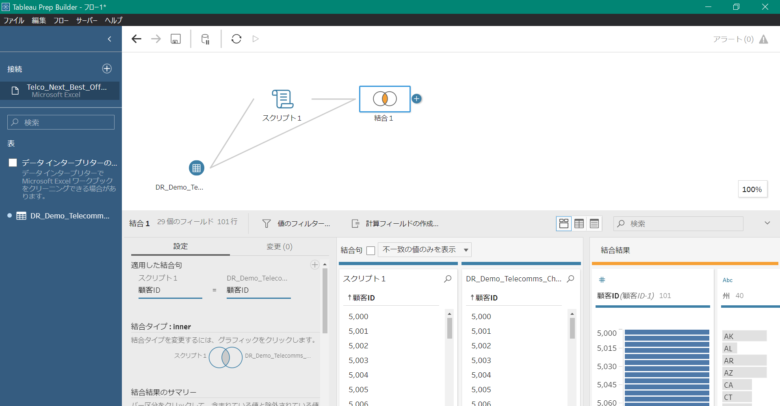
ここまでがTableau Prep Builderで行う作業です。
次にTableau Desktopで結果の可視化を行っていくため、「結合1」のアイコン上で右クリックをして、「Tableau Desktopでプレビュー」を選択すると、自動でTableau Desktopが開かれます。
開かれた状態のTableau Desktopが下記の画像になります。
まず左の欄にある「州」にカーソルを合わせたら右クリックをして、「地理的役割」、「都道府県/州」の順に選択します。
次に、左の欄から、「州」を画面上部の列の欄まで、「予測確率_Daytime plan」を画面上部の行の欄までそれぞれドラッグ&ドロップします。
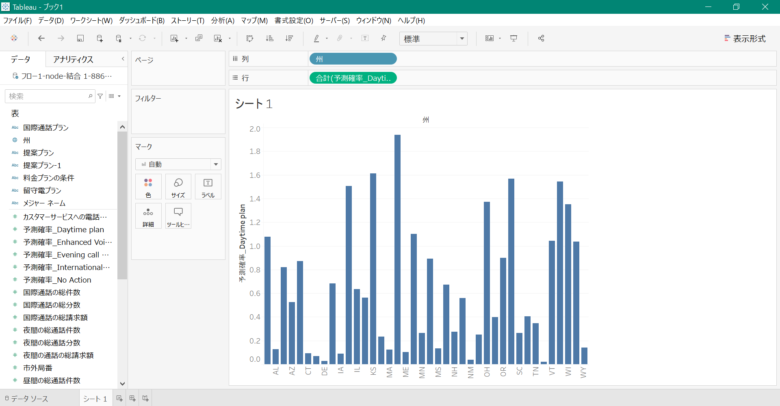
今回、「予測確率_Daytime plan」を平均で表示させるため、行に表示された「予測確率_Daytime plan」にカーソルを合わせたら右クリックをして、「メジャー」、「平均」の順で選択します。
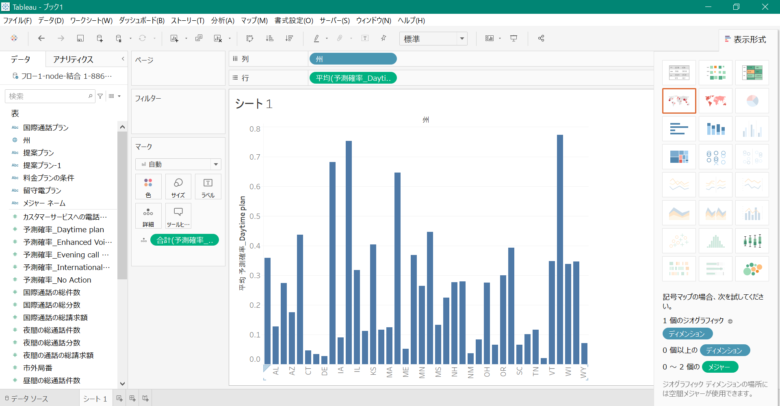
そうすると、下記の画像のように「州」ごとの「予測確率_Daytime plan」が平均値で可視化されます。
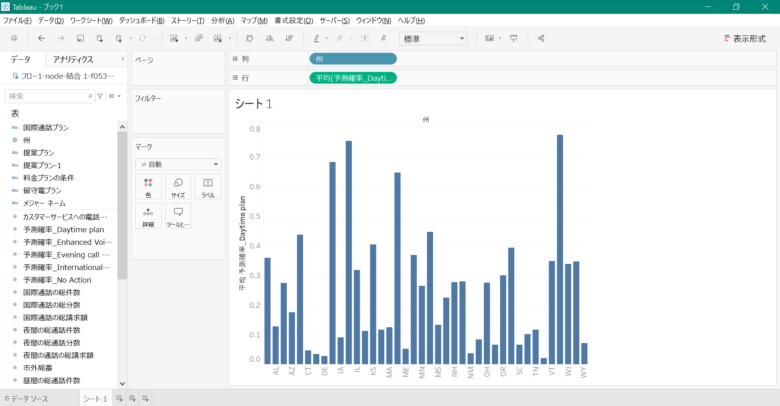
このままだとまだ少し見にくいため、地図上で可視化をしていきます。
まず、右上の「表示形式」から上から2行目、左から2列目の地図のアイコンをクリックすると下記の画像のように表示されます。
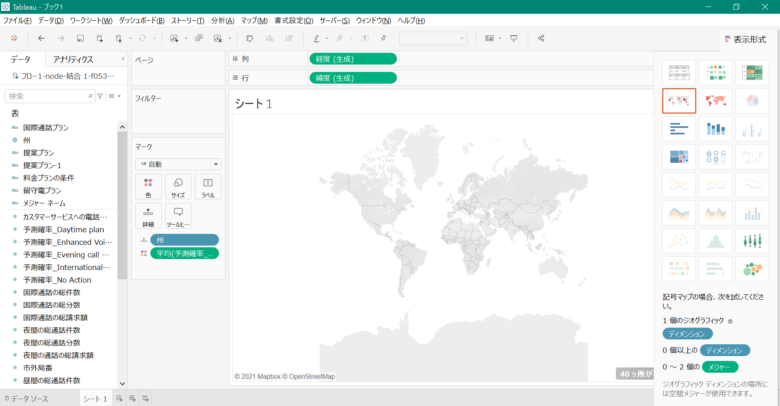
しかし、まだどこの地図情報なのかを認識できていないため、設定をする必要があります。
地図の右下の「40ヶ所不明」をクリックして、「地図の編集」をクリックします。
下記の画像のように画面が表示されたら、今回扱うデータは米国を基準としているため「国/地域」を「米国」に変更して、「OK」ボタンをクリックします。
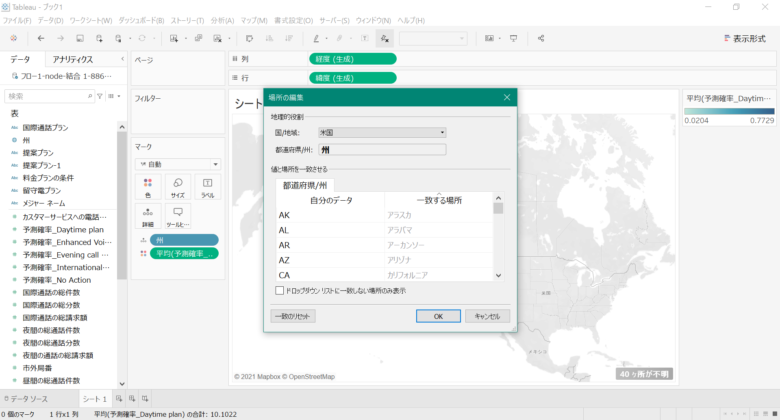
下記の画像にようになりましたでしょうか?
まだ地図上の色の表示が分かりにくいため、色の設定を変えていきます。
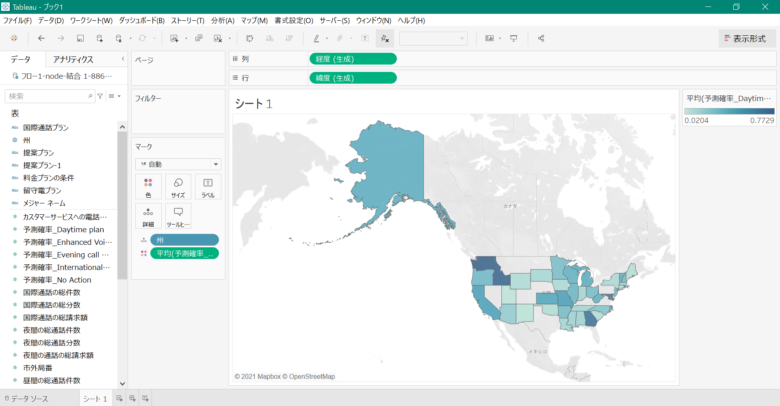
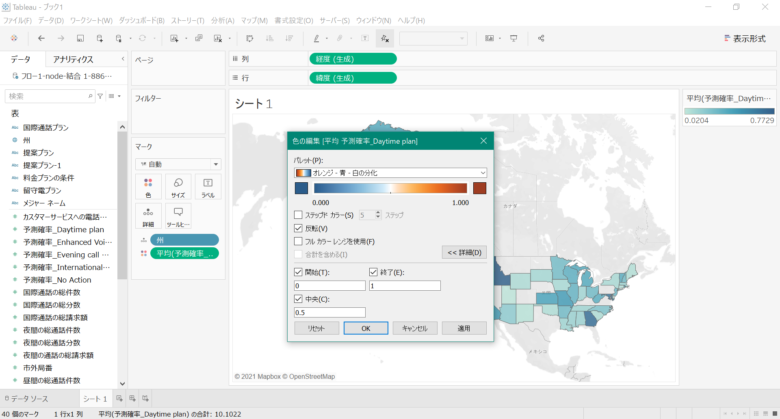
画面の右の欄にある「平均(予測確率_Daytime Plan)」から「色の編集」を選択します。
色を変えるため、「パレット」にある「自動」から今回は「オレンジ-青-白の分化」を選択して、反転にチェックを入れます。
次に色のグラデーション具合を変えるため「詳細」から「開始」を0、「終了」を1、「中央」を0.5に設定して、「OK」ボタンをクリックします。
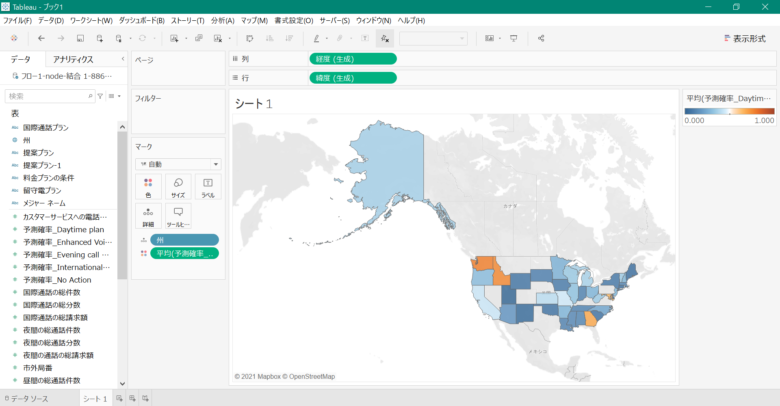
そうすると、下記の画像のようになります。先ほどと違い確率が0から1の範囲で可視化され、とても見やすくなりましたね。
6.おわりに
このブログでは、DataRobotを使ってデータの読み込みから、機械学習モデルを自動的に構築しました。次にTableauを使って予測結果とテストデータの結合、および可視化を行いました。今回デプロイしたモデルはリーダーボードの最上段のものでしたが、他にも様々なモデルが精度や予測速度別に作成されているため、確認してみてください。Tableauでも地図以外に円グラフなど、用途によって可視化方法も工夫できるため、ぜひ使ってみてください。
スキルアップAIは日本初のDataRobot AI 教育パートナーであり、DataRobotに関連する講座として「現場で使えるAIプランニング・プロジェクト推進基礎講座(DataRobot活用編)」を提供しています。こちらはAI活用におけるプロジェクト推進を体系的に学び、加えてPoCフェーズをDataRobotで体験することができる実践的な講座となっています。是非受講をご検討ください。
今回はモデルの作成にDataRobotを使用しましたが、同じく AutoML サービスとして Google Cloud の BigQuery ML を使用し、Tableauを使って可視化した事例も公開しています(SQLだけでモデルが作れる!BigQuery ML による自動モデル作成と Tableau による可視化)。是非こちらの記事もご覧ください。
今回の記事の内容は、毎週水曜日の夜に実施している無料の勉強会「スキルアップAIキャンプ」の第40回「DataRobot によるモデル構築~デプロイの流れを体験してみよう」で紹介した演習を元にしています。スキルアップAIキャンプでは、この記事のような実践的な内容を無料で提供しています。こちらも是非参加をご検討ください。

【監修】スキルアップAI 取締役CTO 小縣信也
AI指導実績は国内トップクラス。「太陽光発電発電量予測および異常検知」など、多数のAI開発案件を手掛けている。日本ディープラーニング協会主催2018E資格試験 優秀賞受賞、2019#1E資格試験優秀賞受賞。著書「徹底攻略ディープラーニングE資格エンジニア問題集」(インプレス)。

公開日:














